| Lesson 8 | ASCII and Unicode |
| Objective | Explain what ASCII and Unicode are. |
ASCII vs. Unicode
As we reflect on the evolution of information technology, it becomes evident why Unicode was adopted over ASCII with the progression of time. This transition, driven by the need for a more inclusive and globally aware computing environment, highlights the vibrant and diverse nature of our world.
In essence, the adoption of Unicode over ASCII is a reflection of our world's wonderful diversity and the need for technology to be as inclusive and comprehensive as possible. It's a testament to how technology adapts to meet the ever-expanding horizons of human communication and expression.
- Global Diversity and Inclusivity: ASCII, limited to 128 characters, was primarily designed for the English language. As the digital age expanded globally, the need for a character encoding system that could encompass a wide array of languages and symbols became paramount. Unicode, with its capacity to represent over 143,000 characters, embraces the rich tapestry of languages around the world, including those with non-Latin scripts like Chinese, Arabic, and many others.
- Consistency Across Platforms: Before Unicode, different systems used their own encoding schemes to represent non-ASCII characters, leading to compatibility issues and data corruption when transferring text between systems. Unicode introduced a universal standard, ensuring that text appears consistently across different platforms and devices.
- Support for Historical and Special Characters: Beyond contemporary language use, Unicode supports historical scripts, mathematical symbols, and various special characters. This allows for a broad range of scholarly, scientific, and creative expressions that were not possible with ASCII.
- Facilitating International Communication: In our interconnected world, the ability to communicate across languages and cultures is crucial. Unicode facilitates this global dialogue, enabling people from different parts of the world to exchange information seamlessly.
- Future-Proofing: Unicode is designed to be extensible. As new characters or symbols need representation, Unicode can accommodate these additions, ensuring that it remains relevant and comprehensive as our communication needs evolve.
In essence, the adoption of Unicode over ASCII is a reflection of our world's wonderful diversity and the need for technology to be as inclusive and comprehensive as possible. It's a testament to how technology adapts to meet the ever-expanding horizons of human communication and expression.
Computers store text using character codes. The most prevalent computer character set is the American Standard Code for Information
Interchange, more commonly known as ASCII[1] (pronounced "ask-ee"). The ASCII character set represents each character with a 7-bit binary code (the decimal numbers 0 to 127).
The first 32 codes in the ASCII character set are used for control functions such as line feed, tab, escape, and carriage return. The remaining 96 codes are used for alphanumeric English characters, as shown in the following table.
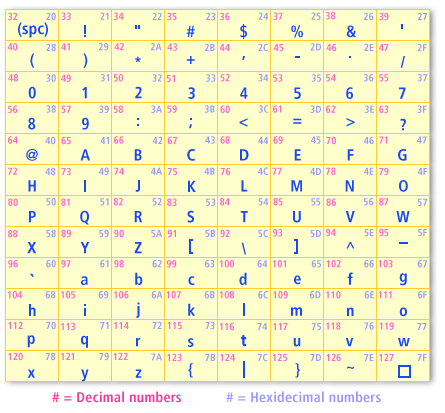
From this table we see that the letter A is represented by the code 65. In binary this code is
This lesson concludes our investigation of how a computer stores numbers and text and wraps up this module.
1000001, and in hexadecimal it is 41. ASCII works reasonably well for basic text in English and many other Western European languages, but to support characters in any language along with technical symbols, ASCII does not have nearly enough character codes. The Unicode Standard is a 16-bit character encoding that provides character codes for all of the characters used in the written languages of the world. Unicode also provides character codes for a wide range of mathematical symbols and other technical characters. With 16 bits Unicode can represent 65,536 different characters and symbols. The Unicode codes 32 to 127 represent the same characters as the ASCII codes,
thus, the 16-bit Unicode code for the letter A is also the decimal number 65. For additional information on the Unicode Standard please refer to the Resources page. Unicode: A 16-bit character encoding.This lesson concludes our investigation of how a computer stores numbers and text and wraps up this module.
Floating PointNumbers Ascii Unicode - Quiz
Click the Quiz link below to test your understanding of floating-point numbers and the ASCII and Unicode character codes.
Ascii Unicode -Quiz
Ascii Unicode -Quiz
[1]ASCII: A 7-bit character encoding.